Parametric Memory Cannot Replace Retrieval: Why Titans-Style Neural Memory Fails for Cross-File Symbol Resolution
We integrate Titans-style parametric memory into Qwen 3.5-9B and evaluate on CrossCodeEval for cross-file code completion. Across four architecture iterations, parametric memory produces zero measurable improvement over a memory-ablated baseline (1.0% EM vs 1.0% EM, an underpowered comparison given the base model's 2-7/200 solve rate), while explicit context concatenation yields 2.5x higher exact match. Per-sample analysis points to a mechanism-task mismatch: inner-loop SGD on a low-dimensional MLP compresses lossily, but cross-file symbol resolution requires lossless recall of specific token sequences.
- titans
- memory
- negative-result
- code-completion
- retrieval
- methodology
Abstract
Test-time parametric memory, where an MLP's weights are updated via inner-loop gradient descent to store contextual information, has shown promise for language modeling (Titans, TTT). We investigate whether this mechanism can replace explicit cross-file context retrieval for code completion, a task requiring precise recall of function signatures, type annotations, and import statements across files. Through four architecture iterations on Qwen 3.5-9B-Base (a DeltaNet-attention hybrid) evaluated on CrossCodeEval, we find that parametric memory produces zero measurable improvement over an ablation baseline where memory is disabled. Explicit context concatenation, by contrast, yields 2.5x higher exact match rates on the same model. The base model solves only 2-7 of 200 tasks in any mode, so the evaluation is underpowered to distinguish memory's contribution from noise on the aggregate delta alone; the per-sample mechanism analysis, not the delta, carries the argument. Memory and ablation produce byte-identical predictions on 75-79% of samples, and every concat success involves retrieving a specific symbol name that memory fails to store. This points to a mechanism-task mismatch: inner-loop SGD on a low-dimensional MLP compresses information lossily, while cross-file code completion requires lossless retrieval of high-entropy symbolic tokens. We identify three compounding failure modes, provide a taxonomy distinguishing compression-appropriate tasks from retrieval-appropriate tasks, and release our evaluation pipeline and ablation data to support future work on memory-augmented code models.
1. Introduction
Cross-file code completion is a practically important task. When writing code in a multi-file project, developers routinely reference functions, classes, and types defined in other files. Models that can use cross-file context produce more accurate completions. The standard approach, concatenating relevant cross-file snippets into the prompt (Ding et al., 2023), is effective but consumes valuable context window space.
Persistent parametric memory offers an appealing alternative. Instead of explicitly placing cross-file context in the prompt, the model could memorize relevant information from other files during a priming phase, then recall it during generation. This is the core premise of Titans (Behrouz et al., 2025) and Test-Time Training layers (Sun et al., 2024): a small MLP whose weights are updated at inference time via gradient descent, allowing the model to learn from new context without modifying its main parameters.
We attempted exactly this integration, installing Titans-style memory modules into Qwen 3.5-9B-Base, a hybrid architecture combining 24 DeltaNet (linear attention) layers with 8 full-attention layers. Over four architecture iterations and three training runs, we found that:
- Memory-augmented generation performs identically to the memory-ablated baseline (1.0% EM vs 1.0% EM on CrossCodeEval).
- Explicit context concatenation remains effective (2.5-3.5% EM), confirming cross-file information is valuable when accessible.
- The model learns to suppress the memory signal during training; forcing it back in via a gate floor slightly degrades generation (-0.3 to -1.1 Edit Similarity vs ablation, with 95% confidence intervals crossing zero).
These results are not artifacts of poor implementation. We validate that the architecture produces gradients correctly (1000x larger gate gradients with additive injection vs. prepended tokens), that cross-file training data produces higher gate utilization (2-3x higher gates), and that the training pipeline converges normally (eval loss 0.763). Our analysis points to a fundamental failure: parametric memory, as integrated here, did not encode the specific, high-entropy facts that cross-file symbol resolution requires. Sections 5.3 and 7 state what this evidence can and cannot support.
2. Background
2.1 Titans Persistent Memory
Titans (Behrouz et al., 2025) introduces a neural memory module, a depth-2 MLP with SiLU activation, whose weights serve as persistent memory. The memory is updated via inner-loop gradient descent:
W←W−η∇WLmem(W;x)W \leftarrow W - \eta \nabla_W \mathcal{L}_{mem}(W; x)W←W−η∇WLmem(W;x)
where Lmem\mathcal{L}_{mem}Lmem is a self-supervised loss (typically prediction error on the current input). Three integration strategies are proposed: Memory as Context (MAC, prepending memory tokens), Memory as Gate (MAG), and Memory as Layer (MAL, replacing attention). We implement MAC and a novel additive variant.
2.2 CrossCodeEval
CrossCodeEval (Ding et al., 2023) is a benchmark for cross-file code completion introduced at NeurIPS 2023. Each sample consists of a prompt (incomplete code), cross-file context (relevant snippets from other files in the same repository), and a ground-truth completion. The task specifically targets completions that require information from other files: function names, argument types, class attributes. We use the Python split with the line_completion_rg1_unixcoder_cosine_sim retrieval configuration (2,665 samples; we evaluate on 200 samples).
2.3 Qwen 3.5-9B Hybrid Architecture
Qwen 3.5-9B-Base uses a hybrid design: 24 DeltaNet layers (linear attention with recurrence) interleaved with 8 full-attention GQA layers at indices 3, 7, 11, 15, 19, 23, 27, and 31. The model has 256K native context. We install memory modules on the 8 full-attention layers, as these serve as information-mixing layers between DeltaNet blocks. DeltaNet itself is a form of linear recurrence, so the model already has implicit memory in 24 of 32 layers.
3. Method
3.1 Architecture Iterations
V1: Memory as Context (MAC). Following Titans' MAC strategy, we prepend N=8 memory tokens to the attention input at each equipped layer. The memory MLP (dim=512) is updated via inner-loop SGD after each forward pass.
V2: Additive Injection. We replace MAC with direct residual injection:
hout=Attention(h)+σ(g)⋅fmem(Wretrieve⋅h)h_{out} = \text{Attention}(h) + \sigma(g) \cdot f_{mem}(W_{retrieve} \cdot h)hout=Attention(h)+σ(g)⋅fmem(Wretrieve⋅h)
where fmemf_{mem}fmem is the memory MLP, WretrieveW_{retrieve}Wretrieve is a learnable projection (4096 to 512), and ggg is a scalar gate initialized at σ(0)=0.5\sigma(0) = 0.5σ(0)=0.5. This eliminates the attention bypass path present in MAC.
V2 + Gate Floor. To prevent gate collapse during frozen-base training, we clamp σ(g)≥0.15\sigma(g) \geq 0.15σ(g)≥0.15.
3.2 Training Configurations
| Config | Base Model | Trainable | Data | Steps |
|---|---|---|---|---|
| V1 (MAC) | + LoRA r=32 | All | StarCoderData (single-file) | 6,200 |
| V2 (crossfile) | + LoRA r=64 | All | Synthetic file pairs | 5,000 |
| V2 (frozen) | Frozen 9B | Memory only (17M) | Repo-grouped StarCoderData | 10,000 |
The frozen-base configuration trains only retrieve projections (8 x Linear(4096, 512)) and context gates (8 scalars), totaling 16.8M parameters (0.19% of model).
3.3 Data
For the frozen-base experiment, we pre-process the Python subset of StarCoderData (Lozhkov et al., 2024): 12.8M files grouped by repository, filtered to 10,000 repos with 3 or more files, 5 or more stars, and at least one intra-repo import. Files within each repo are sorted by directory depth (definitions before usage) and processed sequentially with memory persisting across files within a repo.
3.4 Evaluation Protocol
We evaluate four modes on CrossCodeEval:
- Memory: Prime memory with cross-file snippets via forward passes (memory MLP updates), then generate from prompt only.
- Ablation: Same checkpoint, gates forced to σ(−100)≈0\sigma(-100) \approx 0σ(−100)≈0 (memory disabled).
- Concat: Cross-file context concatenated into prompt (standard baseline).
- No-context: Prompt only, no cross-file information.
The critical comparison is memory vs. ablation: any positive delta is attributable to the memory mechanism. We also compare against vanilla Qwen 3.5-9B-Base (no memory modules, no training) as the unmodified baseline.
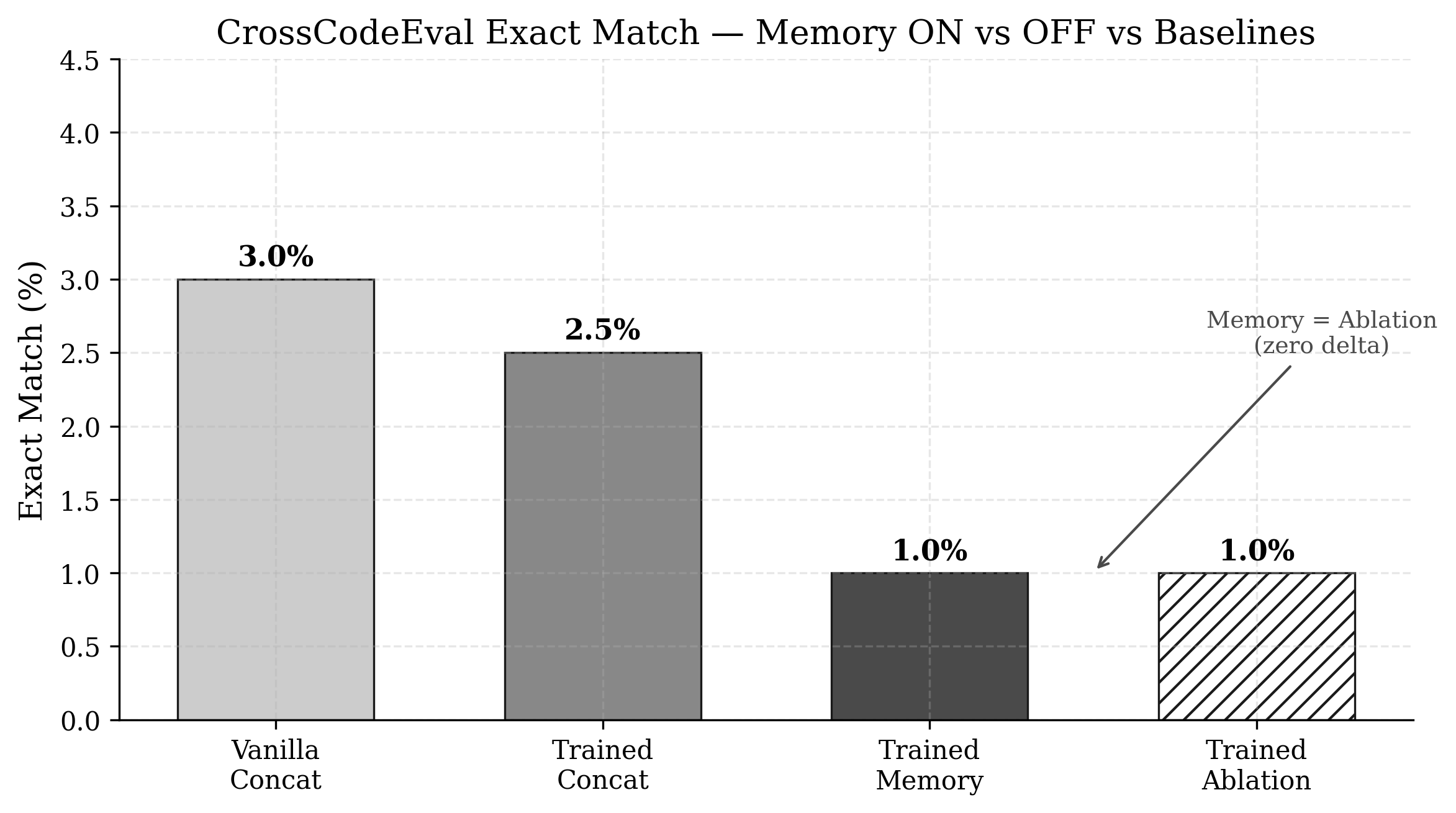 Figure 4: Exact Match comparison across vanilla Qwen baseline and trained model modes. Memory and ablation produce identical results (zero delta).
Figure 4: Exact Match comparison across vanilla Qwen baseline and trained model modes. Memory and ablation produce identical results (zero delta).
4. Results
4.1 V1: MAC Bypass
Gates showed zero movement after 6,200 steps of explicit forcing. The model's self-attention learned to assign near-zero weight to the prepended memory tokens. This failure mode is consistent with findings in soft-prompt literature (Lester et al., 2021): appended tokens can be ignored if the model finds them uninformative.
Finding 1: Attention-based memory injection (prepending tokens) does not guarantee memory utilization.
4.2 V2: Architecture Validates, Synthetic Data Causes Forgetting
Additive injection produced 1000x larger gate gradients than MAC. On synthetic cross-file data (Python file pairs with explicit imports), gates stayed 2-3x higher than single-file training (0.10-0.28 vs approximately 0.07). However, the model trained exclusively on synthetic data produced 0% EM on CrossCodeEval due to catastrophic forgetting of real code patterns.
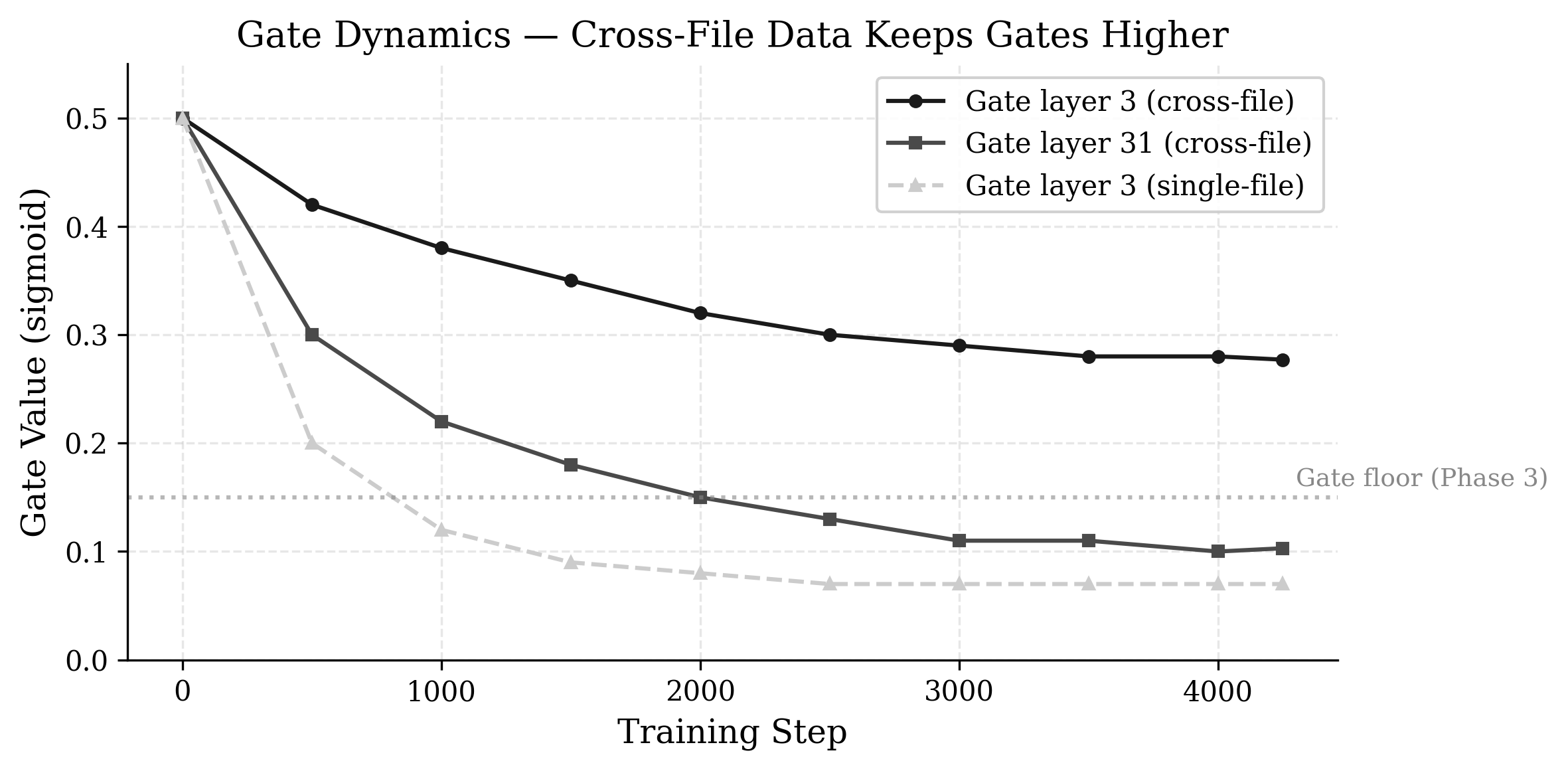 Figure 3: Gate values during Phase 2 training. Cross-file data (solid lines) keeps gates 2-3x higher than single-file data (dashed). The Phase 3 gate floor at 0.15 is shown for reference.
Figure 3: Gate values during Phase 2 training. Cross-file data (solid lines) keeps gates 2-3x higher than single-file data (dashed). The Phase 3 gate floor at 0.15 is shown for reference.
Finding 2: Additive injection correctly forces gradient flow through memory. Cross-file data produces measurably higher gate utilization. But distribution mismatch between training data and evaluation causes catastrophic forgetting.
4.3 V2 Frozen Base: Null Result
| Mode | EM (%) | Edit Sim (%) |
|---|---|---|
| Memory (trained, gates active) | 1.0 | 44.6 |
| Ablation (trained, gates zeroed) | 1.0 | 45.7 |
| Concat (cross-file in prompt) | 2.5 | 46.3 |
| No-context (prompt only) | 1.0 | 45.8 |
Vanilla Qwen baseline (no memory, no training):
| Mode | EM (%) | Edit Sim (%) |
|---|---|---|
| Concat | 3.0 | 45.6 |
| No-context | 1.0 | 45.6 |
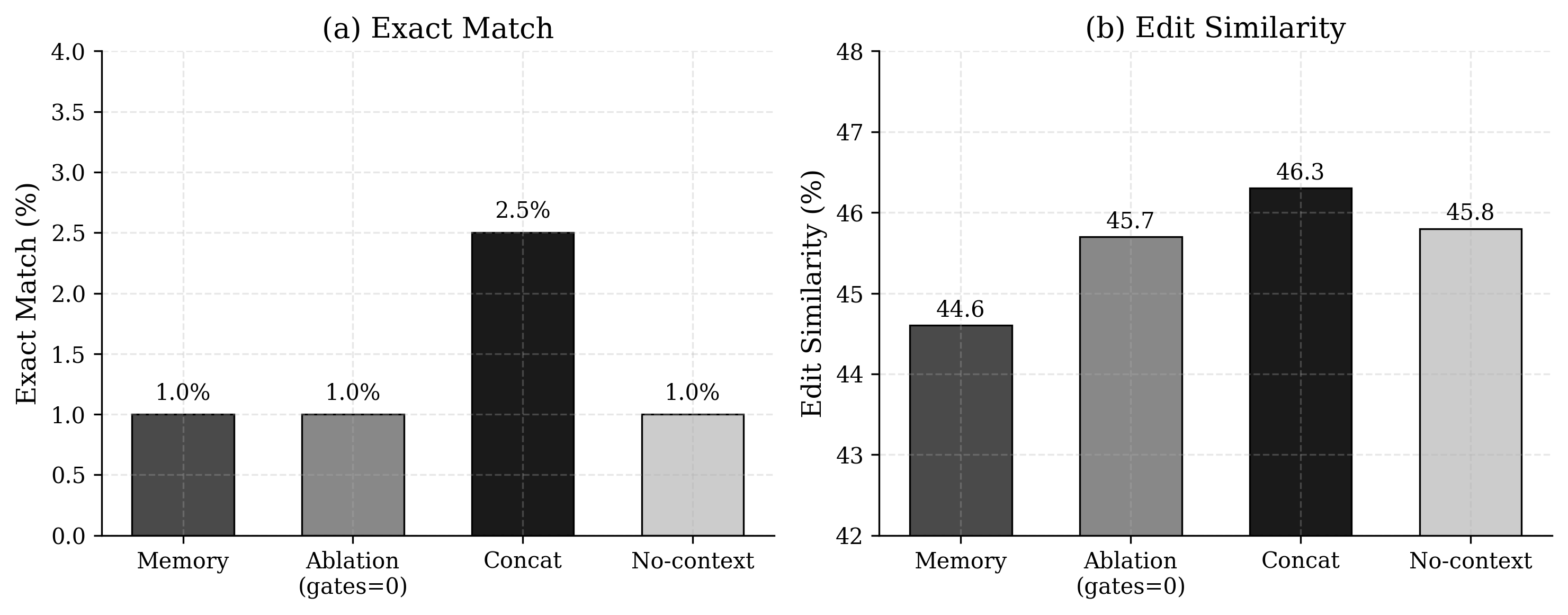 Figure 1: CrossCodeEval results across four evaluation modes. Memory ON produces identical EM to ablation (gates zeroed) and no-context baselines.
Figure 1: CrossCodeEval results across four evaluation modes. Memory ON produces identical EM to ablation (gates zeroed) and no-context baselines.
Memory ON equals memory OFF equals no-context, all at 1.0% EM. Percentile-bootstrap 95% confidence intervals (10,000 resamples over the 200 per-sample scores): memory 1.0% EM [0.0, 2.5], ablation 1.0% [0.0, 2.5], concat 2.5% [0.5, 5.0], no-context 1.0% [0.0, 2.5]. The paired memory-ablation EM delta is exactly zero: both modes solve the same two samples, which no-context also solves. Memory adds no new solves anywhere in the run.
On Edit Similarity, ablation outperforms memory by 1.1 points (paired 95% CI [-2.4, +0.1], crossing zero). An earlier version of this post read that gap as evidence the memory signal is incoherent noise, but the floor forces an untrained signal into the residual stream by construction, so degradation is expected. The cleaner reading: the model learns to suppress memory, and forcing the signal back in hurts. The suppression is the finding; the degradation is its corollary.
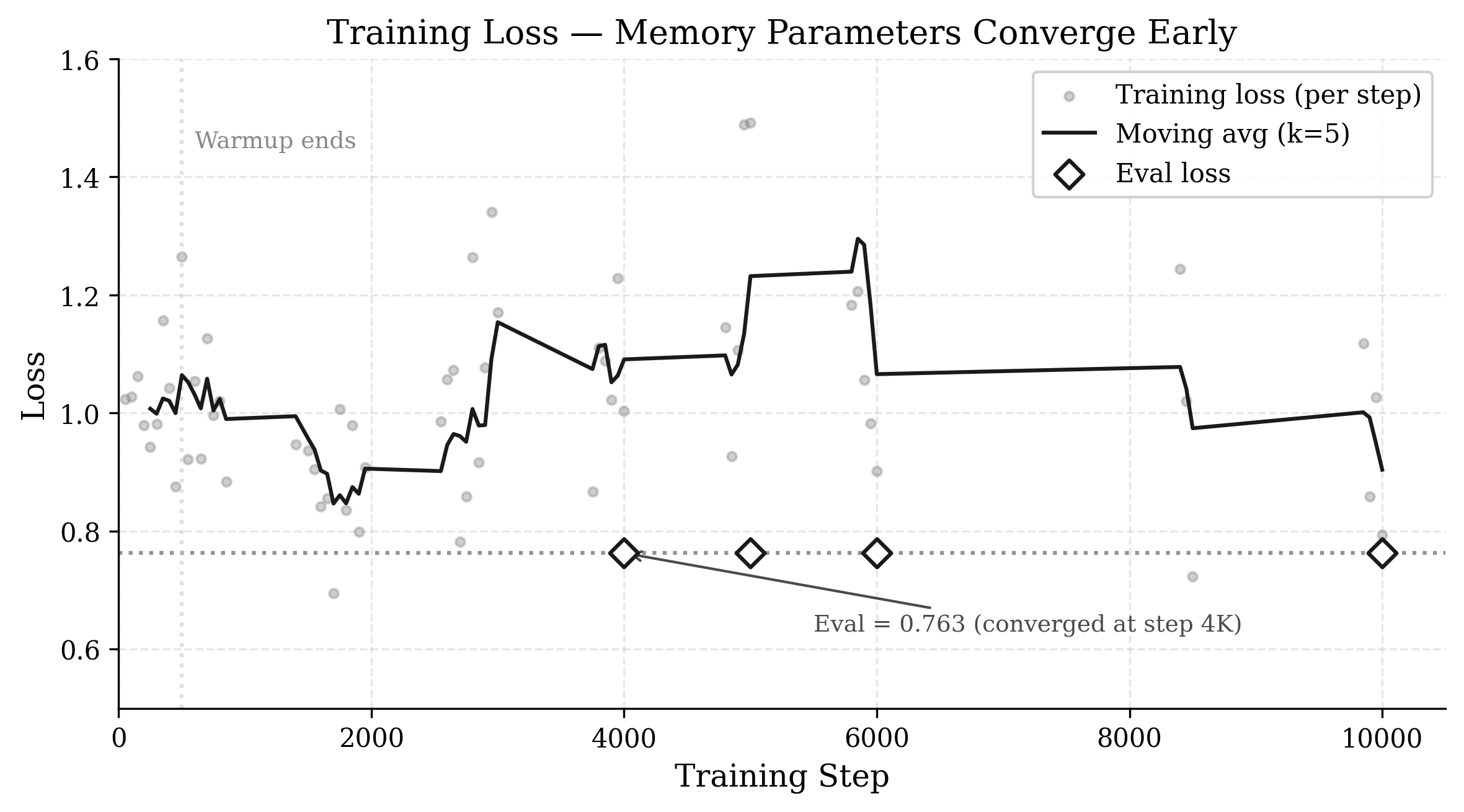 Figure 2: Training loss over 10,000 steps. Eval loss converges at 0.763 by step 4,000 and never improves, consistent with the model minimizing memory's influence within the gate floor constraint.
Figure 2: Training loss over 10,000 steps. Eval loss converges at 0.763 by step 4,000 and never improves, consistent with the model minimizing memory's influence within the gate floor constraint.
An unexplained baseline gap. Published CrossCodeEval baselines report 7B-class models reaching 5-15% EM with retrieved cross-file context (Ding et al., 2023). Our vanilla Qwen 3.5-9B concat baseline reaches 3.0% EM (95% CI [1.0, 5.5]) on a newer, larger base. We do not have an explanation; candidate causes are harness effects (prompt template, stopping criteria for line completion, EM post-processing). This is an open validity threat: if the harness suppresses solve rates across all modes, the benchmark as run has little discriminative power, and the memory comparison inherits that weakness. Debugging it precedes any full-set rerun (Section 7).
4.4 Projection Unification
We identified a store/retrieve projection mismatch: the memory MLP is trained using store_key_proj (frozen orthogonal) but queried using retrieve_proj (learned). Unifying these at inference time reduced but did not eliminate the EditSim gap (-1.1 narrowed to -0.3, paired bootstrap 95% CI [-1.8, +1.2]), while EM remained at 1.0%. Both gaps have confidence intervals crossing zero. The mismatch was real but not the primary failure mode.
5. Analysis
5.1 Per-Sample Failure Analysis
Examining the 7 samples where concat achieves exact match reveals a consistent pattern: concat succeeds when the correct completion requires a specific symbol name defined in another file.
| Sample | Ground Truth | Concat | Memory / Ablation |
|---|---|---|---|
| /283 | HEADER_NAME), "noai") | exact match | robots_header), "noai") |
| /18 | init_parser(subparser) | exact match | REGISTER(subparser) |
| /416 | from_tikz(d["initial_graph"]) | exact match | ikz_to_graph(d["initial_graph"]) |
| /445 | vecdot(vec1, vec2) | exact match | gram_schmidt_coeff(vec1, vec2) |
| /525 | _distance_metric, dim=self._dim) | exact match | EMBEDDING_SPACE, dim=self._dim) |
In every case, the model with explicit context retrieves the exact symbol name (HEADER_NAME, init_parser, from_tikz, vecdot). The memory-augmented model generates a plausible but incorrect name. It knows the shape of the answer (a function call, a constant reference) but not the specific token. This is the compression-retrieval distinction in concrete form: the MLP retains distributional patterns but loses exact identifiers.
Memory and ablation produce byte-identical predictions on 151 of 200 samples (75.5%) in the projection-unified run and 158 of 200 (79.0%) in the main run. This statistic deserves more weight than the aggregate delta. On three quarters of the benchmark, priming the memory changes nothing about the output; where outputs differ, neither mode is systematically better, and both hallucinate different wrong answers. Memory perturbs generation without informing it. Given the low base solve rate, this per-sample identity is the most direct evidence that the module stores nothing the generator uses.
5.2 The Information Bottleneck
The memory MLP has two layers of dimension 512, totaling 524,288 parameters. An earlier version of this section argued that each inner-loop SGD step contributes a rank-1 perturbation, bounding capacity at roughly k×512k \times 512k×512 scalars after kkk steps. That derivation was wrong: a single step over a multi-token snippet sums per-token outer products (our gradient kernel averages over all token positions), so one update can have rank up to min(S,512)\min(S, 512)min(S,512), and for our 1,024-token priming chunks it is potentially full-rank. No clean rank-counting bound holds.
The bottleneck argument is therefore qualitative, not a scalar count. All snippets are compressed into a single shared 524K-parameter regression under a mean-squared prediction loss, with no per-token addressing: successive snippets interfere in superposition, and retrieval passes every query through the same fixed nonlinear map. Concat mode provides 4,096 tokens, each a 4096-dimensional key-value pair individually addressable via attention. The model can attend to any specific token to retrieve any specific fact; the MLP retains only the regression surface fit to them.
| Parametric Memory | Concat | |
|---|---|---|
| Storage | One shared 524K-parameter MLP; snippets superposed with interference | ~4,096 tokens, each an addressable 4096-dim KV pair |
| Access pattern | Fixed nonlinear MLP | Selective attention over tokens |
| What survives | Distributional patterns | Exact token sequences |
Scaling the MLP dimension does not resolve this efficiently. At dim=4096 with 50 inner-loop steps, the memory update would require approximately 800M FLOPs per token, comparable to simply running a forward pass over the 4096-token context through the transformer. Parametric memory is less efficient than attention for high-entropy retrieval, not merely insufficiently sized. Increasing capacity converges to the cost of explicit retrieval.
5.3 Taxonomy: When Does Parametric Memory Work?
We propose a task taxonomy based on our analysis:
| Task Property | Parametric Memory | Explicit Retrieval |
|---|---|---|
| Information entropy | Low (distributional) | High (symbolic) |
| Precision required | Approximate | Exact tokens |
| Context volume | Small (style, preferences) | Large (code, documents) |
| Example tasks | Style adaptation, domain calibration, persona | Code completion, QA, fact lookup |
Parametric memory is well-suited for tasks requiring distributional adaptation: learning that "this codebase uses snake_case" or "this author writes short sentences." It is poorly suited for tasks requiring exact recall: retrieving that get_user_by_email takes email: str and returns Optional[User].
This is not a binary distinction. A hybrid approach using parametric memory for distributional context alongside explicit retrieval for symbolic facts may prove effective, though we leave this to future work.
We must be direct about the epistemic status of this taxonomy: we did not run a positive control, a task on which parametric memory should succeed, on the same architecture and training setup. Without one, our data cannot distinguish "parametric memory cannot do symbolic retrieval" from "our 17M-parameter frozen-base integration does not work at all." The concrete experiment is distributional and constructible from the same repo-grouped data: predict a repository's naming convention or style (snake_case versus camelCase, import idioms) after priming on its files. Success would localize the failure to the task; failure would indict the setup. Until it is run, the mechanism-task mismatch is a hypothesis consistent with our evidence, not a demonstrated boundary (Section 7).
5.4 Why Freezing the Base Does Not Explain the Result
A natural objection: we froze 9B parameters and trained only 17M. Could joint training produce better memory representations?
We argue no, for two reasons. First, if memory encoded useful information, we would expect a non-zero delta between memory ON and memory OFF. We observe exactly zero, but with only 2-7 base-solvable samples the delta had roughly five effective opportunities to move, so the zero is weak evidence alone. The stronger evidence is per-sample: byte-identical predictions on 75-79% of the benchmark (Section 5.1), indicating memory stores nothing the generator uses rather than something useful the frozen base cannot exploit. Second, our V2 cross-file experiment did train the full model (with LoRA), and while gates stayed higher (0.10-0.28), the model's completions on real code were unusable (0% EM) due to distribution mismatch. The frozen base preserved code quality (1.0% EM matches vanilla Qwen) while cleanly isolating memory's contribution, which turned out to be zero.
Additionally, Qwen 3.5's 24 DeltaNet layers are themselves a form of linear recurrence (parametric state compression). The model already has implicit memory in 75% of its layers, so 8 additional explicit modules may provide marginal capacity for distributional patterns the DeltaNet layers already capture. This confound cuts both ways. Defensively, it suggests part of our null could reflect redundancy: a hybrid base has less to gain from explicit memory. But it equally limits generalization: most interest in Titans-style memory concerns pure-attention transformers with no recurrent state, and our result does not speak to them. The direct test is repeating the frozen-base protocol on a pure-attention 7-8B model (Section 7).
5.5 The Absence of Meta-Learning
Our training uses create_graph=False for the inner-loop update, meaning the outer optimizer cannot account for the effect of memory updates on subsequent retrieval. The outer loop optimizes retrieve projections assuming fixed MLP weights, while the inner loop continuously mutates them. This is a known limitation addressed by MAML-style meta-learning (Finn et al., 2017), but enabling second-order gradients would approximately double memory consumption and training time, which is prohibitive for a 9B model on a single A100 (80GB).
We note that the original Titans paper also uses first-order approximations for their larger-scale experiments, so our setup is consistent with the published approach.
6. Related Work
Titans (Behrouz et al., 2025) introduces the neural memory module we build on. Their evaluation focuses on language modeling perplexity and simple retrieval tasks where stored information is lower-entropy than cross-file code. Our work extends their evaluation to a high-entropy symbolic task and identifies conditions under which the mechanism fails.
Test-Time Training (Sun et al., 2024) uses self-supervised objectives to adapt model weights at inference. TTT-Linear uses linear attention as the test-time objective, avoiding the MLP bottleneck. Our findings suggest that replacing the MLP with a linear mapping may alleviate but not eliminate the capacity constraint for high-entropy tasks.
RETRO (Borgeaud et al., 2022) and Memorizing Transformers (Wu et al., 2022) augment transformers with explicit key-value retrieval over stored representations. These approaches preserve the attention-over-tokens inductive bias that makes concat effective. Our results support the view that explicit retrieval is the correct mechanism for high-entropy cross-file information.
Infini-attention (Munkhdalai et al., 2024) compresses past context into a fixed-size state via attention-weighted averaging rather than gradient-based MLP updates. This provides higher effective capacity than parametric memory while remaining more efficient than full attention.
Linear Transformers as Fast Weight Programmers (Schlag et al., 2021) provides theoretical grounding for why linear attention layers (like DeltaNet) can serve as associative memory. Our base model's 24 DeltaNet layers are already performing this function, which may explain why additional explicit memory modules provide no benefit.
CrossCodeEval (Ding et al., 2023) provides the evaluation framework we use. Their published baselines show 7B models achieving 5-15% EM with context concatenation, well above our vanilla concat result (3.0% EM) on a newer 9B base. We treat this gap as an open validity threat rather than evidence of consistency (Section 4.3).
GradMem (Kuratov et al., 2026) demonstrates that gradient-based memory updates work for associative recall tasks where stored information is compact. This is consistent with our taxonomy: parametric memory succeeds when information entropy is low relative to capacity.
7. Limitations
- Statistical power. We evaluate on 200 of 2,665 CrossCodeEval samples, and the base model solves only 2-7 in any mode, so the memory-vs-ablation comparison had roughly five effective opportunities to show a difference. The zero delta is consistent but underpowered as a standalone claim (bootstrap CIs in Section 4.3), and the concat advantage over memory (paired EM delta +1.5, 95% CI [0.0, +3.5]) is itself marginal. Named experiment: the full 2,665-sample CrossCodeEval evaluation, gated on resolving the baseline gap below.
- Unexplained baseline gap. Our vanilla concat baseline (3.0% EM) sits well below published 7B baselines (5-15% EM); likely harness effects, unresolved (Section 4.3). Debugging this precedes the full-set rerun.
- Single model family. Qwen 3.5-9B only, with the DeltaNet confound cutting both ways (Section 5.4). Named experiment: replicate the frozen-base protocol on a pure-attention 7-8B model.
- Memory dimension. We test only dim=512. Larger dimensions could provide more capacity, though our FLOP analysis (Section 5.2) argues this converges to the cost of explicit retrieval.
- No meta-learning. Enabling
create_graph=Truemight allow more effective memory representations. We did not test this due to memory constraints on a single A100. - No positive control. The strongest limitation; without it the mechanism-task mismatch remains a hypothesis (Section 5.3). Named experiment: repo naming-convention/style prediction from the same repo-grouped StarCoderData, with the identical memory setup.
8. What Works Instead
Our results point directly to what should work for cross-file code completion: mechanisms that preserve token-level access to cross-file context.
Retrieval-Augmented Generation (RAG). The simplest approach: retrieve relevant cross-file snippets via embedding similarity or BM25, concatenate into the prompt. Our concat mode (2.5-3.5% EM) validates this works. The cost is context window consumption.
KV-Cache Augmentation. Store key-value representations from cross-file context and inject them via cross-attention (Borgeaud et al., 2022; Wu et al., 2022). This preserves per-token representations without consuming prompt space. The engineering effort is moderate but the mechanism is proven.
Compressive Attention. Infini-attention (Munkhdalai et al., 2024) compresses past context into a fixed-size state via attention-weighted averaging rather than gradient-based MLP updates. This provides higher effective capacity than parametric memory while remaining more efficient than full attention.
The common thread: all successful approaches maintain some form of token-level or attention-weighted access to the original context. Parametric memory fails here specifically because it discards token identity during compression.
9. Conclusion
We present a negative result: across four architecture iterations, Titans-style parametric memory did not improve cross-file symbol resolution on a 9B-parameter hybrid model. The failure is not architectural (additive injection works mechanically) or data-related (repo-grouped training data produces appropriate gradients). Our analysis points to a mechanism-task mismatch: the lossy compression of a low-dimensional MLP written by gradient updates is incompatible with the high-entropy symbolic retrieval that cross-file code completion demands.
Our per-sample analysis makes this concrete. When the ground truth is HEADER_NAME, the model with explicit context produces HEADER_NAME. The model with parametric memory produces robots_header. It gets the concept right but the name wrong. That is what lossy compression looks like.
Two caveats bound the claim. The evaluation is underpowered: with 2-7 base solves in any mode and an anomalously low concat baseline, the zero memory-ablation delta is not by itself distinguishable from noise; the mechanism analysis is what carries the argument. And absent a positive control, the mechanism-task mismatch is our best-supported hypothesis, not a demonstrated boundary of the method. Section 7 names the three experiments that would close these gaps.
We encourage researchers working on memory-augmented models to evaluate against tasks that test the specific information requirements of their target application. Parametric memory is a useful mechanism for distributional adaptation but should not be expected to replace explicit retrieval for high-entropy symbolic tasks.
References
- Behrouz, A., et al. (2025). Titans: Learning to Memorize at Test Time. arXiv:2501.00663.
- Borgeaud, S., et al. (2022). Improving language models by retrieving from trillions of tokens. ICML.
- Ding, Y., et al. (2023). CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion. NeurIPS.
- Finn, C., Abbeel, P., & Levine, S. (2017). Model-agnostic meta-learning for fast adaptation of deep networks. ICML.
- Kuratov, Y., et al. (2026). GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent. arXiv:2603.13875.
- Lester, B., Al-Rfou, R., & Constant, N. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning. EMNLP.
- Lozhkov, A., et al. (2024). StarCoder 2 and The Stack v2. arXiv:2402.19173.
- Munkhdalai, T., et al. (2024). Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention. arXiv:2404.07143.
- Schlag, I., et al. (2021). Linear Transformers Are Secretly Fast Weight Programmers. ICML.
- Sun, Y., et al. (2024). Learning to (Learn at Test Time): RNNs with Expressive Hidden States. ICML.
- Wu, Y., et al. (2022). Memorizing Transformers. ICLR.